Incident Management: Unterschied zwischen den Versionen
Andrea (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
Andrea (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
||
| Zeile 16: | Zeile 16: | ||
</itpmch> | </itpmch> | ||
<imagemap> | <imagemap> | ||
Image:ITIL-Wiki-english-es.jpg|ES - EN - Incident Management| | Image:ITIL-Wiki-teilen.jpg|right|diese Seite teilen|141px | ||
rect 0 | rect 55 0 99 36 [https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fwiki.de.it-processmaps.com%2Findex.php%2FIncident_Management&hl=de_DE&source=IT%20Process%20Wiki diese Seite auf LinkedIn teilen] | ||
rect | rect 97 0 141 36 [https://twitter.com/intent/tweet?url=https%3A%2F%2Fwiki.de.it-processmaps.com%2Findex.php%2FIncident_Management&text=%23ITILwiki%20%7C%20Incident%20Management%20-%20Prozessbeschreibung%0A%E2%96%BA&lang=de&via=itprocessmaps diese Seite auf Twitter teilen] | ||
desc none | |||
</imagemap> | |||
<imagemap> | |||
Image:ITIL-Wiki-english-es.jpg|ES - EN - Incident Management|163px | |||
rect 76 0 114 36 [https://wiki.es.it-processmaps.com/index.php/ITIL_Gestion_de_Incidentes esta página en español] | |||
rect 115 0 163 36 [https://wiki.en.it-processmaps.com/index.php/Incident_Management this Page in English] | |||
desc none | desc none | ||
</imagemap> | </imagemap> | ||
<br style="clear:both;"/> | <br style="clear:both;"/> | ||
'''<span id="Überblick">Ziel:</span>''' <html><span id="md-webpage-description" itemprop="description"><i>Incident Management</i> verwaltet alle Incidents über ihren gesamten Lebenszyklus. Das primäre Ziel dieses ITIL-Prozess besteht darin, einen IT Service für den Anwender so schnell wie möglich wieder herzustellen.</span></p> | '''<span id="Überblick">Ziel:</span>''' <html><span id="md-webpage-description" itemprop="description"><i>Incident Management</i> verwaltet alle Incidents über ihren gesamten Lebenszyklus. Das primäre Ziel dieses ITIL-Prozess besteht darin, einen IT Service für den Anwender so schnell wie möglich wieder herzustellen.</span></p> | ||
Version vom 27. April 2017, 11:39 Uhr


Ziel: Incident Management verwaltet alle Incidents über ihren gesamten Lebenszyklus. Das primäre Ziel dieses ITIL-Prozess besteht darin, einen IT Service für den Anwender so schnell wie möglich wieder herzustellen.
Deutsche Bezeichnung: Incident Management
Teil von: Service Operation (Servicebetrieb)
Prozess-Verantwortlicher: Incident Manager
Prozess-Beschreibung
Incident Management nach ITIL V3 unterscheidet zwischen Incidents (Service-Unterbrechungen) und Service Requests (d.h. Standard-Anfragen der Anwender, wie z.B. das Zurücksetzen von Passworten etc.). Service-Anfragen werden nun nicht mehr vom Incident Management gelöst; stattdessen gibt es einen neuen Prozess Request Fulfilment.
Mit ITIL V3 wurde ein dedizierter Prozess zur Behandlung von Notfällen - sog. Major Incidents - eingeführt. Hinzu gekommen ist auch eine Prozess-Schnittstelle zwischen dem Event Management und dem Incident Management: Bedeutsame Events lösen die Anlage eines Incident aus.

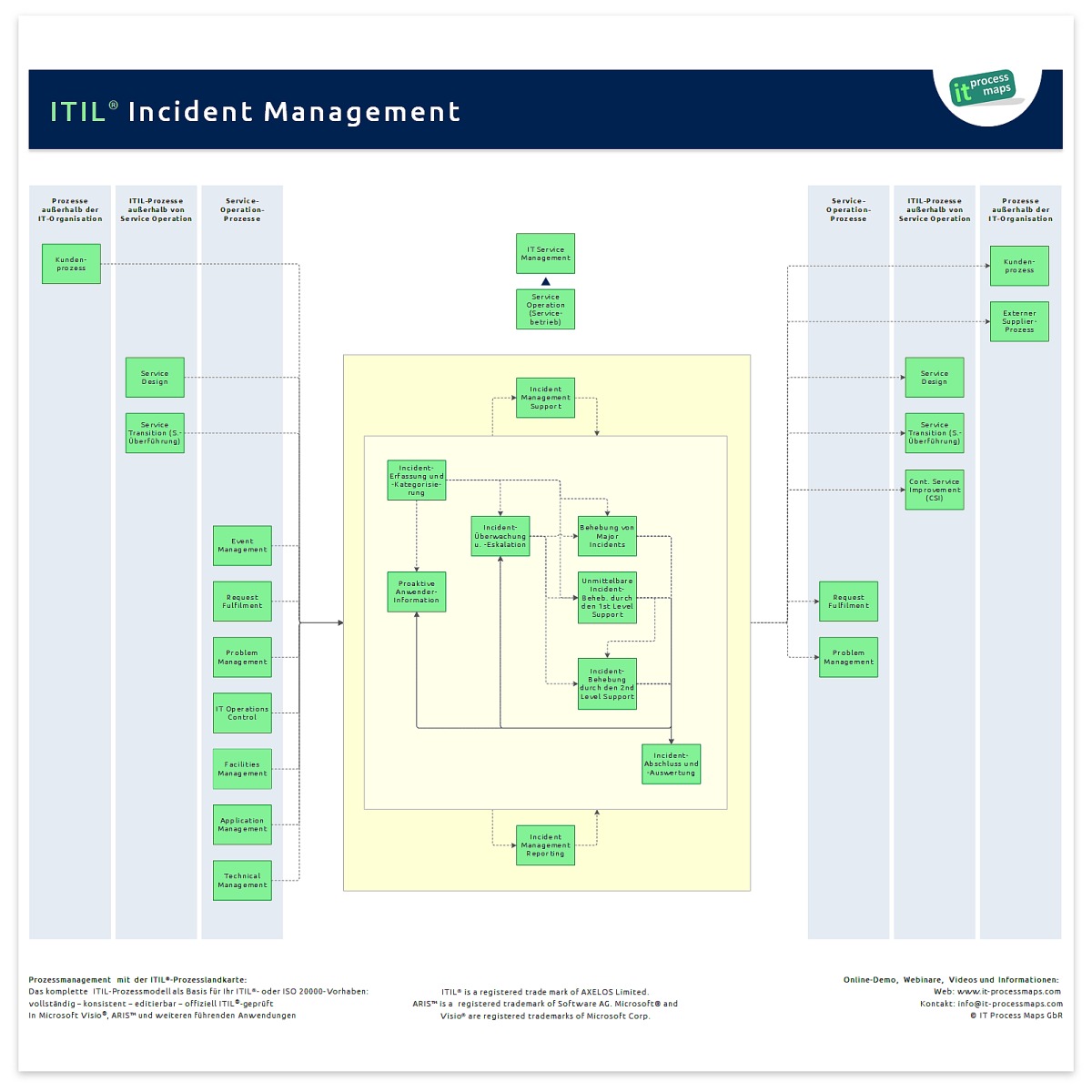
ITIL 2011 behandelt Incident Management in noch größerer Detailtiefe: Das Übersichts-Diagramm illustriert die wichtigsten Schnittstellen des Prozesses (siehe Abb. 1).
Überarbeitet wurden die Empfehlungen zur "Incident-Priorisierung" (vgl. Checkliste Incident-Priorität).
Im Incident-Management-Teilprozess Unmittelbare Incident-Behebung durch den 1st Level Support wird nun deutlich gemacht, dass Incidents (wenn möglich) mit bestehenden Problems und Known Errors in Beziehung gesetzt werden sollen.
Um klarer herauszustellen, wann genau das Problem Management vom Incident Management eingeschaltet werden soll, wurden die Teil-Prozesse Unmittelbare Incident-Behebung durch den 1st Level Support und Incident-Behebung durch den 2nd Level Support erweitert. Dabei wird betont, dass Services so schnell wie möglich wiederhergestellt werden sollen. Sollte die eigentliche Ursache des Incidents nicht mit einem Minor Change bzw. in der vorgeschriebenen Lösungszeit behoben werden, so ist die Hilfe des Problem Managements einzufordern.
Der Teil-Prozess Incident-Abschluss und -Auswertung enthält den ausdrücklichen Hinweis, zu prüfen, ob neue Problems, Workarounds oder Known Errors an das Problem Management übermittelt werden müssen.
Teil-Prozesse
ITIL Incident Management umfasst die folgenden Teil-Prozesse:
Incident Management Support
- Prozessziel: Bereitstellen und Pflegen der Werkzeuge, Prozesse, Qualifikationen und Regeln für eine effektive und effiziente Bearbeitung von Incidents.
Incident-Erfassung und -Kategorisierung
- Prozessziel: Aufzeichnen und Priorisieren der Incidents mit angemessener Sorgfalt, um eine rasche und effektive Fehlerlösung zu ermöglichen.
Unmittelbare Incident-Behebung durch den 1st Level Support
- Prozessziel: Ein Incident soll innerhalb der vereinbarten Lösungszeit gelöst werden. Ziel ist die schnelle Wiederherstellung des IT-Service ggf. mit Hilfe eines Workarounds. Sobald es klar wird, dass der 1st Level Support den Incident nicht selbst lösen kann oder wenn die festgelegte Zeit für eine Lösung durch den 1st Level überschritten wird, wird der Incident an eine geeignete Gruppe innerhalb des 2nd Level Supports übergeben.
Incident-Behebung durch den 2nd Level Support
- Prozessziel: Ein Incident soll innerhalb der vereinbarten Lösungszeit gelöst werden. Ziel ist die schnelle Wiederherstellung des Service ggf. mit Hilfe eines Workarounds. Falls erforderlich, werden spezialisierte Support-Gruppen oder die Supplier (3rd Level Support) mit einbezogen. Sofern die Behebung der Grundursache nicht möglich ist, wird ein Problem Record erzeugt und die Fehlerbeseitigung an das Problem Management übergeben.
Behebung von Major Incidents
- Prozessziel: Lösung eines Major Incidents (schwerwiegenden Incidents). Major Incidents verursachen gravierende Unterbrechungen der Geschäftstätigkeiten und müssen mit höherer Dringlichkeit gelöst werden. Das Ziel besteht in der schnellen Wiederherstellung des Service, ggf. mit Hilfe eines Workarounds. Falls erforderlich, werden spezialisierte Support-Gruppen oder die Supplier (3rd Level Support) mit einbezogen. Sofern die Behebung der Grundursache nicht möglich ist, wird ein Problem Record erzeugt und die Fehlerbeseitigung an das Problem Management übergeben.
Incident-Überwachung und -Eskalation
- Prozessziel: Der Bearbeitungsstand offener Incidents soll laufend verfolgt werden, so dass bei zu langen Lösungszeiten rechtzeitig Gegenmaßnahmen eingeleitet werden können.
Incident-Abschluss und -Auswertung
- Prozessziel: Vor dem Schließen eines Incidents soll der angewendete Lösungsweg einer Qualitätskontrolle unterzogen werden. Das Ziel besteht darin, sicherzustellen, dass der Incident tatsächlich gelöst worden ist und dass alle Informationen zur Beschreibung des Lösungswegs in ausreichendem Detail dokumentiert sind. Zusätzlich sollen eventuelle Erkenntnisse aus der Lösung des Incidents für die Lösung künftiger Incidents nutzbar gemacht werden.
Proaktive Anwender-Information
- Prozessziel: Anwender über Service-Ausfälle informieren, sobald diese dem Service Desk bekannt geworden sind, so dass die Anwender in die Lage versetzt werden, sich auf Service-Unterbrechungen einzustellen. Die proaktive Information der Anwender zielt ebenso darauf ab, die Anzahl der Anfragen durch Anwender zu reduzieren. Dieser Prozess ist auch für die Verteilung von sonstigen Informationen an die Anwender zuständig, z.B. Sicherheitswarnungen.
Incident Management Reporting
- Prozessziel: Incident-bezogene Informationen für die anderen Service-Management-Prozesse bereitstellen und Sicherstellen, dass aus aufgetretenen Incidents Verbesserungspotentiale abgeleitet werden.
Definitionen
Die folgenden ITIL-Begriffe und Acronyme (Informations-Objekte) werden in Incident Management zur Darstellung der Prozess-Outputs und -Inputs verwendet:
Anwender-Eskalation
- Eine Eskalation bezüglich der Bearbeitung eines Incidents oder Service Requests, angestoßen von Anwendern, deren Incidents bzw. Aufträge nur mit Verzögerung oder gar nicht bearbeitet werden.
Anwender-FAQs
- Informationen für Anwender zur Selbsthilfe. Diese werden z.B. auf den Support-Seiten des Service-Desks im Intranet zur Verfügung gestellt.
Incident
- Eine ungeplante Unterbrechung oder Qualitätsminderung eines IT-Services bzw. ein Ereignis, das in der Zukunft einen IT-Service beeinträchtigen könnte. Vgl. Incident Record.
Incident-Eskalationsregeln
- Die Regeln für die Incident-Eskalation legen die Hierarchie fest, nach der Incidents eskaliert werden, sowie die Auslöser, die zu Eskalationen führen. Die Auslöser orientieren sich in der Regel am Schweregrad des Incidents und an der voraussichtlichen Lösungsdauer. Siehe auch: Checkliste Incident-Priorität
Incident-Management-Bericht
- Ein Bericht des Incident Managers, der andere Service-Management-Prozesse über aufgetretene Incidents und deren Beseitigung informiert.
Incident-Modell
- Ein Incident-Modell enthält die vordefinierten Maßnahmen zum Umgang mit einem bestimmten Incident-Typ. Auf diese Weise kann gewährleistet werden, dass häufig wiederkehrende Incidents effektiv und effizient bearbeitet werden.
Incident Record
- Ein Datensatz mit allen Angaben zu einem Incident, in dem der Lebenszyklus des Incidents von der Ersterfassung bis zur Schließung dokumentiert ist. Ein Incident ist definiert als ungeplante Unterbrechung oder Qualitätsminderung eines IT-Services. Auch ein Ereignis, das in der Zukunft einen IT-Service beeinträchtigen könnte, ist ein Incident (z.B. der Ausfall einer Festplatte in einem RAID-Verbund). Siehe auch: ITIL-Checkliste Incident Record
Incident-Status-Information
- Eine Nachricht mit Informationen zum aktuellen Stand einer Incident-Bearbeitung an einen Anwender, der zuvor einen Incident gemeldet hat. Statusinformationen werden Anwendern typischerweise an verschiedenen Punkten im Lebenszyklus eines Incidents gesendet.
Major Incident
- Schwerwiegende Incidents, die gravierende Unterbrechungen der Geschäftstätigkeiten verursachen und mit höherer Dringlichkeit gelöst werden müssen. Siehe auch: Checkliste Incident Priorisierung - Major Incidents
Major Incident Review
- Ein Major Incident Review erfolgt, nachdem ein Major Incident aufgetreten ist. Das Review dokumentiert die dem Incident zugrundeliegenden Ursachen (soweit bekannt) und die vollständige Lösungshistorie, sowie Verbesserungsmöglichkeiten bei der Behandlung künftiger Major Incidents.
Meldung einer Service-Unterbrechung
- Die Meldung einer Service-Unterbrechung an das Service-Desk, z.B. von einem Anwender per Telefon oder E-Mail, oder von einem System-Monitoring-Tool.
Priorisierungs-Richtlinie für Incidents
- Die Priorisierungs-Richtlinie für Incidents beschreibt die Regeln für die Zuordnung von Prioritäten zu Incidents und definiert, welche Incidents als Major Incidents zu behandeln sind. Da die Eskalationsregeln für Incidents in der Regel auf Prioritäten basieren, ist die Zuordnung der richtigen Priorität maßgeblich für die angemessene Eskalation von Incidents. Siehe auch: Checkliste Richtlinie Incident-Priorisierung
Proaktive Anwender-Information
- Eine Meldung über bestehende oder unmittelbar bevorstehende Service-Unterbrechungen an die Anwender, damit sich die Anwender auf die Nicht-Verfügbarkeit eines Service einstellen können.
Status-Anfrage
- Eine Anfrage bezüglich des aktuellen Bearbeitungsstands eines Incidents oder Serviceauftrags, typischerweise von einem Anwender gestellt, der zuvor einen Incident oder Service Request gemeldet hat.
Support-Anfrage
- Eine Anforderung zur Unterstützung bei der Behebung eines Incidents oder Problems. Eine solche Anforderung wird üblicherweise vom Incident Management oder Problem Management gestellt, wenn weitere technische Expertise für die Behebung von Incidents oder Problems erforderlich ist.
KPIs | Checklisten
Rollen | Verantwortlichkeiten
Incident Manager - Prozess-Verantwortlicher
- Der Incident Manager ist verantwortlich für die effektive Durchführung des Prozesses "Incident Management" und führt das entsprechende Berichtswesen durch. Er ist die erste Eskalationsstufe für Incidents, falls diese nicht innerhalb der vereinbarten Service Levels gelöst werden können.
1st Level Support
- Der Bearbeiter im 1st Level Support sorgt bei eingehenden Störungsmeldungen für die Registrierung und Einordnung und unternimmt einen unmittelbaren Lösungsversuch zur schnellstmöglichen Wiederherstellung des definierten Betriebszustands eines Service. Ist dies nicht möglich, leitet er die Störung an spezielle Bearbeitergruppen im 2nd Level Support weiter.
2nd Level Support
- Der Bearbeiter im 2nd Level Support übernimmt Störungsmeldungen vom 1st Level Support, die dieser nicht selbständig lösen kann. Bei Bedarf wird er Unterstützung von Herstellern (3rd Level Support) anfordern. Ziel ist die schnellstmögliche Wiederherstellung des definierten Betriebszustands eines Service. Ist keine ursächliche Störungsbeseitigung möglich, übergibt er die Störung zur weiteren Bearbeitung an das Problem Management.
3rd Level Support
- Der Bearbeiter im 3rd Level Support ist typischerweise bei einem Hersteller von Hardware- oder Softwareprodukten ("Supplier") angesiedelt; er wird vom 2nd Level Support mit einbezogen, wenn dies zur Beseitigung von Störungen erforderlich ist. Ziel ist die schnellstmögliche Wiederherstellung des definierten Betriebszustands eines Service.
Major Incident Team
- Das Major Incident Team ist ein dynamisch gegründetes Team von IT-Managern und technischen Experten, normaler Weise unter der Führung des Incident Managers. Es wird einberufen, um gemeinsam die Lösung für einen Major Incident (schwerwiegenden Incident) zu erarbeiten.
| Verantwortlichkeits-Matrix: ITIL Incident Management | |||||||
| ITIL-Rolle / Teil-Prozess | Incident Manager | 1st Level Support | 2nd Level Support | Major Incident Team | Anwend.- system-Analytiker[3] |
Technischer Analytiker[3] | IT-Operator[3] |
|---|---|---|---|---|---|---|---|
| Incident Management Support | A[1]R[2] | - | - | - | - | - | - |
| Incident-Erfassung und -Kategorisierung | A | R | - | - | - | - | - |
| Unmittelbare Incident-Behebung durch den 1st Level Support | A | R | - | - | - | - | - |
| Incident-Behebung durch den 2nd Level Support | A | - | R | - | R[4] | R[4] | R[4] |
| Behebung von Major Incidents | AR | R | - | R | - | - | R |
| Incident-Überwachung und -Eskalation | AR | R | - | - | - | - | - |
| Incident-Abschluss und -Auswertung | A | R | - | - | - | - | - |
| Proaktive Anwender-Information | A | R | - | - | - | - | - |
| Incident Management Reporting | AR | - | - | - | - | - | - |
Erläuterungen
[1] A: Accountable i.S.d. RACI-Modells: Verantwortlich dafür, dass Incident Management als Gesamt-Prozess korrekt und vollständig ausgeführt wird.
[2] R: Responsible i.S.d. RACI-Modells: Verantwortlich für die Ausführung bestimmter Aufgaben in Incident Management.
[3] Zu den Rollen-Beschreibungen...
[4] In Kooperation, je nach Erfordernis: 2nd Level Support-Gruppen sind oft mit Anwendungs- bzw. Technischen Analytikern besetzt
Demo zum Incident Management

Video ansehen: "Die ITIL-Prozesslandkarte - Einführung" [Dauer: 10:58 Min.]
Die kurze Demo zur ITIL-Prozesslandkarte zeigt Inhalte des ITIL-2011-Referenzprozessmodells von IT Process Maps; das Video enthält Informationen zu den Prozessen Service Operation und ITIL Incident Management, wie z.B.
- ITIL-Service-Lifecycle (Detailebene 0)
- Übersicht über ITIL Service Operation (Detailebene 1)
- Übersicht über den Prozess Incident Management (Detailebene 2)
- Detaillierte Aktivitäten im Teil-Prozess "Incident-Behebung durch den 1st Level Support" (Detailebene 3)
Anmerkungen
Von: Stefan Kempter ![]() , IT Process Maps.
, IT Process Maps.
Überblick › Prozess-Beschreibung › Teil-Prozesse › Definitionen
 und ITIL 4")






{kind=link}