Checkliste Incident-Priorität
Definition: Die Incident-Priorität ergibt sich in der Regel aus der Bewertung seiner Auswirkung und Dringlichkeit: Dringlichkeit ('Urgency') ist ein Maß dafür, wie schnell der Incident gelöst werden muss. Auswirkung ('Impact') drückt aus, wie umfangreich der Incident ist und welcher (potentielle) Schaden durch den Incident verursacht werden kann.
ITIL-Prozess: ITIL Service Operation - Incident Management
ITIL 4-Practice: Incident Management
Checklisten-Kategorie: ITIL-Templates
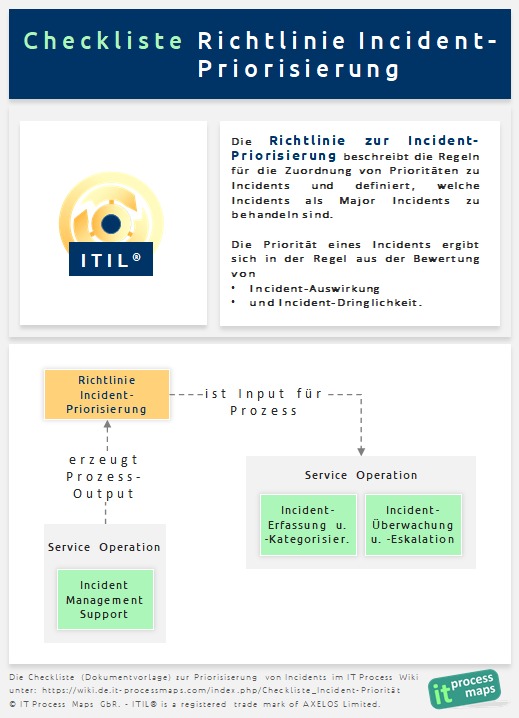
Richtlinie Incident-Priorisierung

Die Richtlinie Incident-Priorisierung beschreibt die Regeln für die Zuordnung von 'Prioritäten zu Incidents' und definiert, welche Incidents als 'Major Incidents' zu behandeln sind. Da die Eskalationsregeln für Incidents in der Regel auf Prioritäten basieren, ist die Zuordnung der richtigen Priorität maßgeblich für die angemessene 'Eskalation von Incidents'.
Incident-Dringlichkeit (Dringlichkeits-Kategorien)
Dieser Abschnitt gibt Incident-Dringlichkeits-Kategorien vor. Die Definitionen müssen auf die jeweilige Organisation genau abgestimmt sein, deshalb ist die folgenden Tabelle lediglich ein Beispiel:
Um die Incident-Dringlichkeit zu bestimmen, wähle die höchste zutreffende Kategorie:
| Kategorie | Beschreibung |
|---|---|
| Hoch (H) |
|
| Mittel (M) |
|
| Niedrig (N) |
|
Incident-Auswirkung (Auswirkungs-Kategorien)
Dieser Abschnitt gibt Incident-Auswirkungs-Kategorien vor. Die Definitionen müssen auf die jeweilige Organisation genau abgestimmt sein, deshalb ist die folgenden Tabelle lediglich ein Beispiel:
Um die Incident-Auswirkung zu bestimmen, wähle die höchste zutreffende Kategorie:
| Kategorie | Beschreibung |
|---|---|
| Hoch (H) |
|
| Mittel (M) |
|
| Niedrig (N) |
|
Incident-Priorität (Prioritäts-Kategorien)
Die Priorität eines Incidents leitet sich aus Dringlichkeit und Auswirkung ab.
Incident Priority Matrix
Wenn Klassen zur Bestimmung von Dringlichkeit und Auswirkung definiert sind, kann eine Dringlichkeits-Auswirkungs-Matrix ("Urgency-Impact Matrix" oder auch "Incident Priority Matrix" genannt) verwendet werden, um Klassen von Prioritäten festzulegen, wie im folgenden Beispiel:
| Auswirkung | ||||
|---|---|---|---|---|
| H | M | N | ||
| Urgency | H | 1 | 2 | 3 |
| M | 2 | 3 | 4 | |
| L | 3 | 4 | 5 | |
| Prioritäts-Code | Beschreibung | Reaktionszeit-Vorgabe | Lösungszeit-Vorgabe |
|---|---|---|---|
| 1 | Kritisch | Sofort | 1 Stunde |
| 2 | Hoch | 10 Minuten | 4 Stunden |
| 3 | Mittel | 1 Stunde | 8 Stunden |
| 4 | Niedrig | 4 Stunden | 24 Stunden |
| 5 | Sehr niedrig | 1 Tag | 1 Woche |
Kriterien für die Behandlung eines Incidents als Major Incident
Major Incidents erfordern die Etablierung eines Major Incident Teams und werden durch den Prozess Behebung von Major Incidents behandelt.
Indikatoren
Über das oben gezeigte Schema hinaus ist es oft angeraten, zusätzliche und leicht verständliche Indikatoren zur Bestimmung von Major Incidents zu definieren. Beispiele für solche Indikatoren sind:
- Bestimmte (Gruppen von) geschäftskritischen Services, Anwendungen oder Infrastruktur-Komponenten sind nicht verfügbar und die voraussichtliche Zeit bis zur Wiederherstellung ist zu lang oder unbekannt (hier ist zu spezifizieren, welche Services, Anwendungen oder Infrastruktur-Komponenten zutreffen)
- Bestimmte (Gruppen von) geschäftskritischen Prozessen ("Vital Business Functions") sind betroffen und die voraussichtliche Zeit bis zur Wiederherstellung der vollständigen Leistungsfähigkeit dieser Prozesse ist übermäßig lang oder unbekannt (hier ist zu spezifizieren, welche geschäftskritischen Prozesse zutreffen)
Bestimmung von Major Incidents
Die Bereitstellung klarer Richtlinien zum Bestimmen von Major Incidents ist oft ein schwieriges Unterfangen, aber der 1st Level Support entwickelt zumeist einen "sechsten Sinn" für diese. Im Zweifelsfall ist es auch besser, auf der sicheren Seite zu bleiben.
Ein Major Incident ist durch seine großen Auswirkungen charakterisiert, insbesondere auch auf Kunden. Beispiele hierfür sind:
- Die Netzwerkanbindung fällt aus und damit ist die Kommunikation des Unternehmens mit der Außenwelt unterbrochen.
- Ein Web-Server fällt wegen unerwartet hoher Belastung aus, z.B. weil viele Kunden zugreifen, um Eintrittskarten zu einer Veranstaltung zu reservieren; dadurch wird es vielen Kunden unmöglich, Eintrittskarten zu erwerben.
- Eine zentrale Datenbank stellt sich als korrupt heraus.
- Mehrere für das Geschäft wichtige Server sind von einem Virus befallen.
- Vertrauliche Informationen zu einer größeren Zahl von Kunden sind in die Öffentlichkeit gelangt.
Darüber hinaus sind alle Katastrophenfälle (die von der IT-Service-Continuity-Strategie und unterstützenden ITSCM-Plänen behandelt werden) als Major Incidents zu bewerten. Zu beachten ist auch, dass unkritische Incidents durch Fehler oder zu lange Inaktivität zu Major Incidents werden können.
Die wichtigsten Eigenschaften von Major Incidents
Die wichtigsten Eigenschaften, an denen sich Major Incidents erkennen lassen, sind unter anderem:
- Eine signifikante Anzahl von Kunden bzw. von wichtigen Kundengruppen ist betroffen.
- Die Kosten bzw. aus dem Incident resultierenden Verluste für Kunden und/oder die Service-Organisation sind beträchtlich.
- Die Reputation des Service-Providers wird wahrscheinlich beschädigt.
UND
- Der Arbeits- und Zeitaufwand zur Lösung des Incidents ist vermutlich groß und es ist sehr wahrscheinlich, dass bestehende Service-Level-Vereinbarungen verletzt werden.
Ein Major Incident ist in aller Regel auch mit der Priorität "Kritisch" oder "Hoch" versehen.
Anmerkungen
Basiert auf: Checkliste "Richtlinie Incident-Priorität" aus der ITIL-Prozesslandkarte.
Von: Stefan Kempter ![]() , IT Process Maps.
, IT Process Maps.
Richtlinie Incident-Priorisierung › Dringlichkeit › Auswirkungen › Kriterien: Major Incidents
 und ITIL 4")






{kind=link}